How to implement appearance-based scene recognition using panoramic images for persistent navigation and mapping in open areas?
The excerpt note is about vision processing and appearance-based recognition using panoramic images for persistent navigation and mapping in open areas from Michael et al., 2010.
Michael Milford, and Gordon Wyeth. “Persistent Navigation and Mapping using a Biologically Inspired SLAM System.” The International Journal of Robotics Research 29, no. 9 (2010): 1131-1153.
The vision system uses panoramic images obtained from a Basler camera, mounted at the central rotation axis of a Pioneer 3DX robot and facing vertically upwards at a parabolic mirror (see fig). Automatic adjustment for global illumination changes is achieved in hardware through gain and exposure control. Local variations in illumination can still be quite severe, such as patches of sunlight on the floor which disappear at night. They use patch normalization to reduce local variation, which has been shown to enable robust scene recognition in varying illuminations (Zhang, 2007), and process only the bottom half of each image to reduce the effects of direct sunlight. The patch normalized pixel intensities, 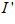 , are given by
, are given by
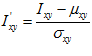
Where 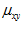 and
and 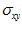 are the mean and standard deviation of pixel values in a patch of size
are the mean and standard deviation of pixel values in a patch of size 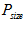 surrounding
surrounding 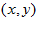 .
.
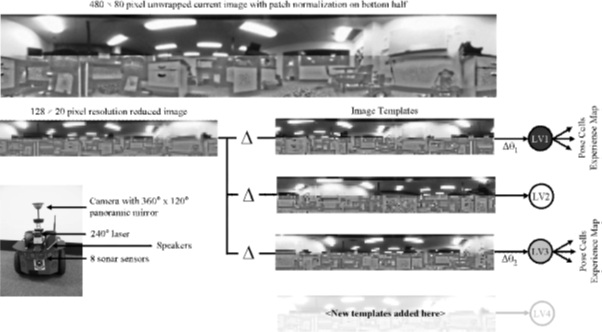
Fig. Vision hardware and vision processing system. A camera and mirror produces panoramas which are unwrapped into 360 degree by 90 degree images. The image is then reduced in resolution, patch normalized to enhance local image contrast and correlated with all template images. Template images that are close matches to the current image activate local view cells, which link to the pose cells and experience map.
Scene Recognition
Since this is an indoor robot application, they assume that the ground surface is locally flat and that the robot is constrained to the ground plane. The recognition process starts with the current unwrapped, patch normalized 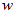 by
by 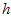 pixels panoramic image, with the
pixels panoramic image, with the 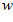 dimension aligned with the ground plane in the real world and the
dimension aligned with the ground plane in the real world and the 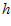 dimension aligned with the vertical plane. Image similarities between the current image and template images are calculated using the cross correlation of corresponding image rows. For each row this correlation can be performed efficiently in the Fourier domain, in which multiplication is equivalent to convolution in the spatial domain:
dimension aligned with the vertical plane. Image similarities between the current image and template images are calculated using the cross correlation of corresponding image rows. For each row this correlation can be performed efficiently in the Fourier domain, in which multiplication is equivalent to convolution in the spatial domain:
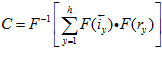
Where 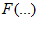 is the Fourier Transform operator and
is the Fourier Transform operator and 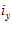 and
and 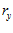 are the pixels rows at
are the pixels rows at 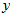 in the current and template images, respectively. The value of the maximum real correlation coefficient gives the quality of the match
in the current and template images, respectively. The value of the maximum real correlation coefficient gives the quality of the match 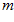 :
:
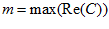
A new image template and local view cell is created if the best match for all current image-template image pairings if below a threshold 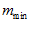 . Fourier transform coefficients are calculated only once for an image and stored by the vision system. As the number of image templates becomes large, computation becomes
. Fourier transform coefficients are calculated only once for an image and stored by the vision system. As the number of image templates becomes large, computation becomes 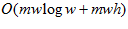 , scaling linearly with the number of templates. Coding optimizations for the Fourier transform, such as the use of the single instruction, multiple data (SIMD) instruction set extension, are implemented using the freely available fast FFIW C library (Frigo and Johnson, 1998).
, scaling linearly with the number of templates. Coding optimizations for the Fourier transform, such as the use of the single instruction, multiple data (SIMD) instruction set extension, are implemented using the freely available fast FFIW C library (Frigo and Johnson, 1998).
Local View Cell Calculation
The match quality scores for each image pair are used to set the activation levels for the corresponding local view cells:
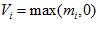 for all
for all 
The local view cell activation level is limited to non-negative values, since the correlation coefficient and hence match quality 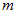 has the range (
has the range (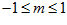 ) .
) .
For further info, please read the Michael et al., 2010.
Michael Milford, and Gordon Wyeth. “Persistent Navigation and Mapping using a Biologically Inspired SLAM System.” The International Journal of Robotics Research 29, no. 9 (2010): 1131-1153.
References
Zhang, A. M. (2007). Robust appearance based visual route following in large scale outdoor environments. Proceedings of the Australasian Conference on Robotics and Automation, Brisbane, Australia, 2007.
Frigo, M. and Johnson, S. G. (2008) Fastest Fourier Transform in theWest An Adaptive Software Architecture for the FFT. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, United States, 1998.